面向外文科技文献的超级科技词表和本体建设
面向外文科技文献的超级科技词表和本体建设课题的目标是:采用国际上先进的知识组织技术和方法,借鉴国内外已有的知识组织系统建设成果与应用经验,构建面向计算机应用的科技知识组织体系(Scientific & Technological Knowledge Organization Systems, STKOS),为我国海量外文科技文献信息的组织和利用提供支撑,实现国家科技文献信息战略资源的有效组织、深度揭示和知识关联,推进基于国家科技文献信息战略资源的知识发现、知识挖掘和知识计算应用示范,整体提升我国科技文献信息机构的知识服务能力。
本课题的具体目标包括:
(1)建成具有一定规模的统一的超级科技词表。超级科技词表预计收集科技词汇素材约1000万条,收录科技术语不少于500万条,科技概念规范名称80万条,其中理学领域科技概念规范名称20万条,工学领域20万条,医学领域30万条,农学领域10万条。在“十二五”前三年争取收词量达到上述目标的70%,基础词库科技术语达到460万条,理工农医领域概念数量达到56万条。
(2)按照本体构建的目标场景和本体生命周期,建立一套本体构建的方法和工具集,以网络化本体为核心,通过动态建模的方法实现本体的重用、重构、映射、关联和模块化,实现非本体的知识组织体系向本体转换,以支持NSTL外文文献的知识发现、语义关联、语义分析、语义计算。并在此基础上,结合“十二五”重大专项,选择4-5个学科方向,构建领域本体。构建1个科研本体,并选择理、工、农、医四个领域领先的科研人员、科研机构、学术会议等,建立科研知识库。
主要任务包括:
(1)规划、设计并建立科技知识组织体系的内容、结构和体系框架,及建立各种类型的标准规范
面向外文科技文献信息的知识组织系统建设和应用示范项目由多个课题组成,涉及到科技知识组织系统内容建设、科技知识组织系统协同工作平台建设、科技知识组织系统示范应用等多个方面,是一个复杂的系统工程。为保障项目建设内容顺利实施,需要形成明确、清晰的科技知识组织体系的内容、结构、体系框架和相应的标准规范。科技知识组织系统由超级科技词表和本体库两部分组成。超级科技词表由基础科技词库、规范概念集和范畴体系三个层次的知识组织体系组成,以此来形成标准规范。
(2)超级科技词表素材采集、评价与遴选
超级科技词表的素材包括两部分来源,一是各种词表、术语表,二是来自作者的关键词和用户检索的关键词等。按照理工农医领域采集国外叙词表、分类法、术语表等,并对其进行对比分析和评价。根据遴选标准从来源词表中遴选出骨干词表(或主流词表)。通过对NSTL海量科技信息资源中的作者关键词和用户检索词进行统计分析、评价,遴选确定作者关键词、用户检索词集等。这些素材作为后续建立超级科技词表和范畴体系的基础。
(3)超级科技词表基础科技词库建设
对已收集素材中的海量科技术语进行形式化汇总、整理、规范、去重、分类等处理,按照统一的基础科技词库元数据结构标准,建设基础科技词库,为超级科技词表建设和概念进一步更新奠定基础。在基础科技词库建设部分主要解决不同词表等异构数据的同构化表示(包括术语表达,属性的继承等),同形异义、异形同义和同形近义等问题。基础科技词库包括基础科技词库元数据和符合SKOS规范的来源词表仓储两部分。
(4)超级科技词表规范概念集建设
超级科技词表的核心是概念,通过对基础科技词库中科技术语进行词形规范、词义规范,并按照概念遴选标准遴选概念,确定概念的规范名称。在规范概念集建设中,以概念为核心,以继承来源骨干叙词表的原有关系为基础,通过概念与原有叙词表来源术语的语义关系,以及概念间的共现关系进行关联,形成以概念为核心的概念集合。通过概念定义、概念范畴、概念间的关系、概念的规范汉译名以及概念被使用的信息多种方式加以完善和扩充。在统一的词表集成框架体系下,形成超级科技词表的规范概念集。
通过规范概念集的建设,可以实现来源词表、术语基于概念的整合;重点解决同义表达的问题。从应用角度看,它能够支持对文献信息内容在概念层面的自动标注,支持自然语言的检索,支持一定意义上的双语检索,支持基于概念层面的智能检索,包括扩检缩检,支持基于关联词表的主题聚类等。
(5)超级科技词表范畴体系建设
范畴是概念的重要属性,用来说明概念所适用的学科或所归属的类。对于文献信息的主题聚类、分类组织及浏览具有重要意义。同时,范畴体系的建设也是科技文献信息通用本体建设的基础,有利于控制通用本体的维度和颗粒度,便于建立通用本体与超级科技词表概念的映射关系,有利于解决因学科交叉、表达产生的维(粒)度不同、冲突和重叠等方面问题。
超级科技词表范畴体系在借鉴或复用现有的范畴体系的基础上,充分考虑主题概念和文献的实际分布,面向未来的应用,确定超级科技词表范畴体系的规模、结构特征和描述机制。
(6)STKOS本体建设
STKOS本体的建设以STKOS超级词表规范概念集为基础,借鉴、整合、开发一套整体的网络化本体建设的方法和工具集,通过动态建模的方法实现本体的重用、重构、映射、关联和模块化,实现非本体的知识组织系统向本体转换,以情境分析为基础采取合作方式来建立本体网络,以支持NSTL外文文献的知识发现、语义关联、语义分析、语义计算。通过领域本体和科研本体的示范建设,为将来NSTL的大规模语义应用奠定基础。
1.总体技术路线
本课题中的外文科技知识组织体系构建技术拟采用目前国际主流的基于多个词表关联集成的本体网络技术路线,并针对我国科技文献处理与服务的具体需求,实行“立足词表,面向本体”的设计与建设原则,采用素材层、超级科技词表层和本体层组成的三层技术架构,总体架构和路线如图1所示。
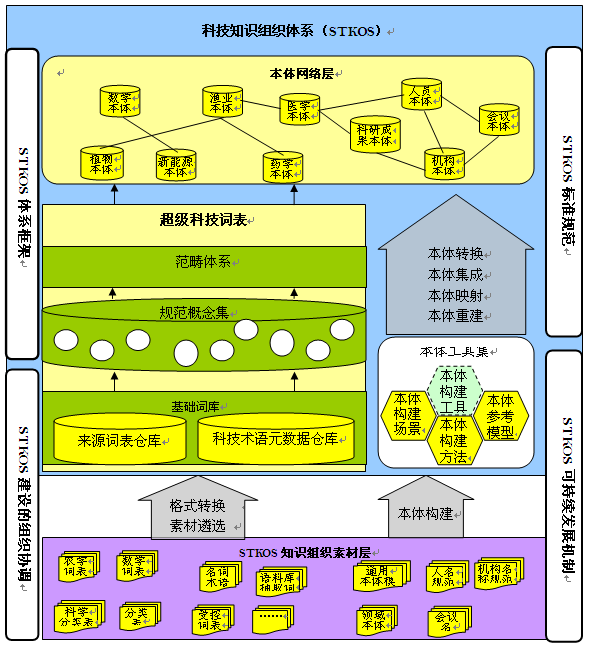
图1 面向外文科技文献的超级科技词表和本体建设总体技术框架和路线
2.超级科技词表总技术路线
超级科技词表体系框架
面向外文文献的超级科技词表是本课题建设的重点,是实现科技文献信息自动标注、智能检索、知识导航、后续应用示范的基础,是网络化本体建设的重要条件,也是资源共享的重要内容。
超级科技词表由五个部分内容组成:素材库、基础词库、STKOS规范概念集、范畴体系、KOS登记库。超级词表体系结构见图2。
素材库:是经采集、遴选、格式规范生成的用于超级科技词表建设的基础知识组织体系素材,素材库素材可以包括各种类型的知识组织体系,如叙词表、分类表、术语表、字词典、用户关键词等。
基础词库:包含了来源KOS素材的术语、用户关键词等各种来源的词汇和术语。基础词库的术语继承了来源KOS的概念体系,同时通过同形异义词、异形同义词、近义词、相关词等识别和关联,构成丰富的词网络。
STKOS规范概念集:STKOS规范概念集是基础词库中遴选出来的重要的科技概念,通过继承、关联、归一等人工规范整理而成的具有规范名称和规范定义的概念。STKOS规范概念是整个超级科技词表中最上层的概念,通过自下而上的层层关联,超级科技词表隐含关联了基础词库的规范术语、基础术语、来源素材概念,形成了术语和概念网络。
范畴体系:按学科体系构建的等级分类表,覆盖了科学技术全部领域,用以组织概念和科技术语,支持超级科技词表建设过程中的术语和概念管理,支持科技文献的自动聚类。
KOS登记库:对知识组织体系素材和经规范的来源KOS的描述与登记。
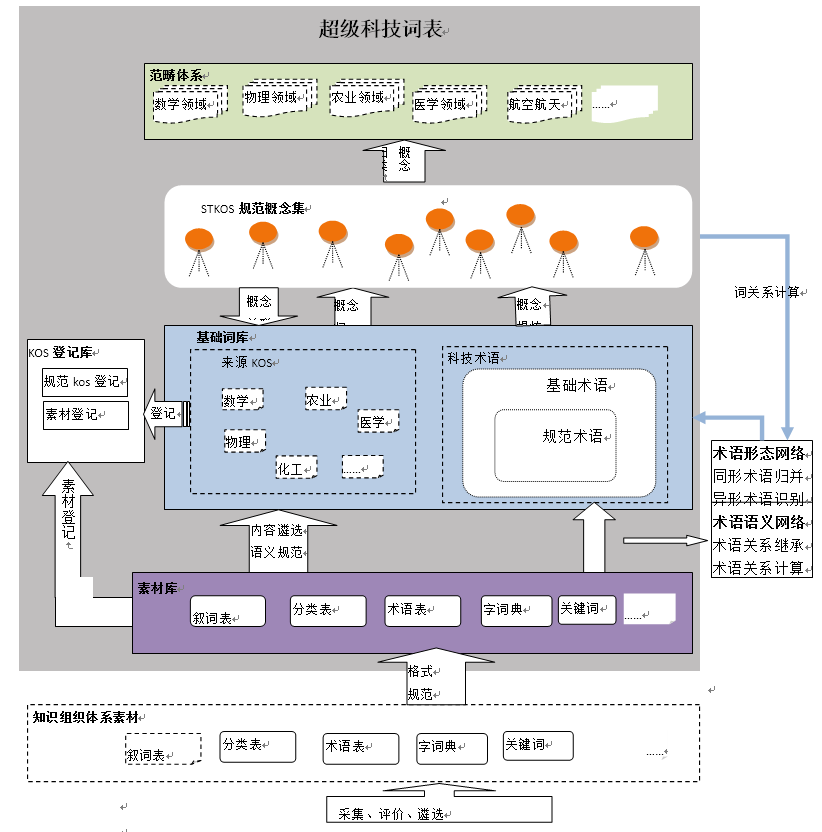
图2超级科技词表体系框架图
超级科技词表的建设方案总体思路是:
①构建以科技术语为基本单元,以概念为核心,以继承来源词表的原有关系为基础,通过概念与来源词表术语的语义关系进行关联,形成以概念为核心的超级科技词表。
②构建超级科技词表,要充分借鉴、继承来源词表中术语的表达形式和已有属性,实现来源术语以概念为中心的整合;同时充分利用多年文献数据库建设的成果,补充、完善超级科技词表的科技术语。
③超级科技词表应包括三个层次,即基础词库层(含遴选确定的来源词表的所有重要信息)、规范概念层(含遴选确定的所有概念,与概念相关的各种关系通过关联的方法从来源词表中继承)和范畴层(便于对NSTL文献信息的主题聚类、分类以及浏览等,辅助检索)。
也就是说,构建超级科技词表,要以来源词表的科技术语为基本单元,以概念为核心,以继承来源骨干叙词表的原有关系为基础,通过概念与原有叙词表来源术语的语义关系,以及概念间的共现关系进行关联,形成以概念为核心的概念网络。通过充分借鉴来源词表的表达形式和已有属性,实现来源词表以概念为中心的整合;同时,结合利用国内多年的国外科技文献数据库的建设成果,进一步补充、完善超级科技词表的科技概念。在概念间关系方面,要充分借鉴、继承和利用其在多个骨干来源叙词表中的关系。并开发相应的工具,检测概念关系的错误和冲突,除非该概念在多个来源词表中的关系存在明显错误或冲突,一般不对其关系属性进行梳理和必须的纠正。另外,为便于对外文科技文献知识内容的主题聚类、分类浏览、资源导航以及智能检索等,在概念集的上层建设概念范畴体系,对概念按范畴体系进行归类。
超级科技词表的建设流程和工作流程
超级科技词表建设流程分三个部分,分别为基础词库层、规范概念集和范畴层的三层技术架构。
素材层:主要由理工农医各专业相关的叙词表、分类表、术语表、词典、关键词、用户检索词等词汇资源组成,素材分单位、按专业由各个单位分别收集并统一保存管理,素材层包括了素材库和KOS登记库,各单位对收集知识组织体系在KOS登记库中进行描述和登记,装入到素材库中。词汇总体规模为1000万,词汇之间不去重。
基础词库:包含各领域具有较高质量和较丰富语义关联的各类词表。包括语义关联丰富的各类领域叙词表,是从科技知识组织素材库经遴选、规范、格式转换而来的,例如医学领域的医学主题词表(MeSH),物理学叙词表(INSPEC),工程叙词表(EI thesaurus),农学叙词表(CABI)等。也包括较高质量的术语表、分类表、关键词、用户检索词等。
基础词库是超级科技词表的基础,基础词库分4层,从下到上分别为来源表基础术语层,基础术语层,规范术语层,基础概念层。来源表基础术语层以记录术语来源的词汇为单位;基础术语层以不同书写方法的词汇为单位;规范术语层是以经过词形规范的术语(包含不同写法的术语)为基本单位;基础概念层是经过同义词归并等机器规范化处理后生成的概念为单位。基础词库的4层结构建设流程如下图3:
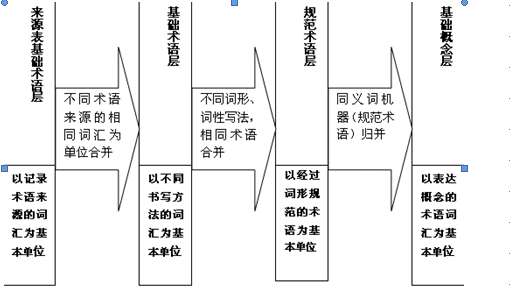
图3基础词库的4层机构建设流程
基础词库的四层结构,包含了从词汇到基础概念的形成过程。鉴于基础概念为机器归并的结果,所以,有部分基础概念还有可能是意义相同的等同概念,这些概念需要人工干预才能识别并归并,这个人工过程将在规范概念层完成。基础词库的词关系支持科技文献信息检索时的扩展检索、缩小检索范围,以及关联检索。
规范概念集:规范概念集是从基础词库的基础概念层中,通过人工干预,将相同含义的基础概念进行归并,将不同属性的同型词区分为不同概念,再经概念遴选或直接全盘使用而形成的,代表了理工农医四大领域主要的领域概念。规范概念集的每个概念连接到一个或多个领域词表的相同含义的概念,规范概念集的每个概念同时向上关联到范畴体系。同时,在规范概念的描述上,每个规范概念含有一个英文的规范名称和一个中文的规范名称。通过规范概念的承上启下的连接和中英文双语的名称对照,使超级科技词表成为一个巨大的词网络系统,能够支持对NSTL海量文献信息的自动标注,支持查全率和查准率的提升,支持按主题的分面组织,支持中英文双语的检索等服务。
范畴体系:范畴体系用来将概念集中的概念组织在学科范畴或语义网络框架下,能够支持文献信息资源的自动分类和检索结果按学科主题聚类。范畴体系将采用现有的比较成熟的分类表或语义网络,初步考虑将采用DDC分类表作为超级科技词表的范畴。
超级科技词表建设的主要任务是调研和采集国外科技领域的知识组织体系及其相关元数据集;从NSTL外文科技文献数据库中抽取作者关键词和用户检索词;构建由来源词表和关键词构成的基础词库;遴选概念,并继承若干部主流的综合性词表和专业词表作为语义关系的继承对象,建立概念与若干来源词表相关属性关系的关联;建立涵盖理工农医的范畴体系,并对概念进行相应范畴体系归类。
超级科技词表数据模型和元数据
为了能向提供词表的管理系统和第三方系统对超级科技词表进行管理、提供服务和有效利用,制订了超级科技词表发布库的元数据方案,用于超级科技词表发布数据库的数据进行规范化描述。
采用统一建模语言(UML)建立超级科技词表数据模型。数据模型图4说明如下:
下面示例的数据模型读作:一个来源概念关联到一个来源词表;一个来源词表关联到1个或多个来源概念。

图4数据模型
根据超级科技词表的总体框架,超级科技词表共包括了6个对象:来源术语、来源词表、科技术语、STKOS规范概念、范畴类、和范畴表。超级科技词表的基本数据模型如下图5:
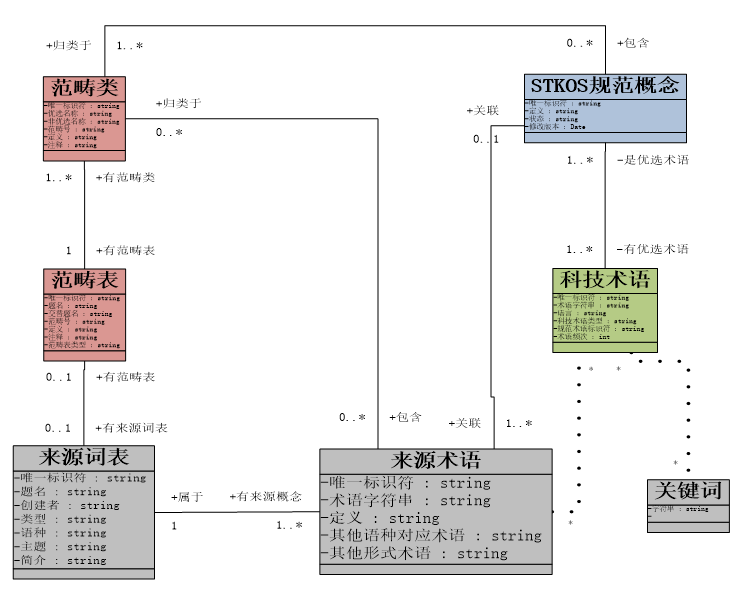
图5超级科技词表基本数据模型
本体层建设技术路线
STKOS本体层的建设是以STKOS超级词表概念网络为基础,通过借鉴、整合、发展一套整体的网络化本体建设的方法和工具集,根据STKOS的知识服务应用示范的需求,将STKOS超级词表及其他知识组织体系进行本体化表达,形成轻量型本体,建立4-5个面向领域应用的本体网络和1个科研本体网络,为将来NSTL的大规模语义应用奠定基础。
STKOS本体层的建设思路是以网络化本体为核心,通过动态建模的方法实现本体的重用、重构、映射、关联和模块化,实现非本体的知识组织体系向本体转换,以情境分析为基础采取合作方式来建立本体网络,以支持NSTL外文文献的知识发现、语义关联、语义分析、语义计算。本体层建设技术路线如图6所示。
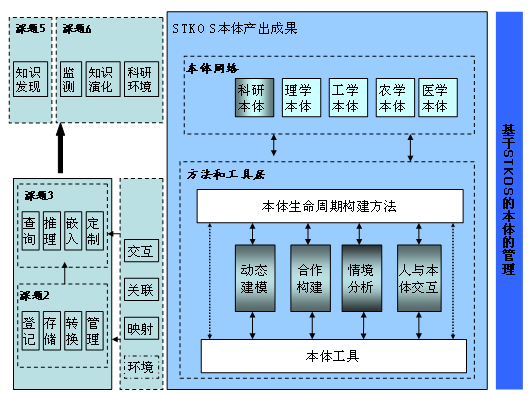
图6 STKOS本体建设技术路线图
课题基于包括NSTL文献关键词、用户检索关键词表在内的975部来源词表中的1,438万来源科技术语和609万基础术语,遵循研制的标准规范,经过对来源术语、科技概念和概念的同义表达、优选词、范畴类别、释义、中文译名等的严格遴选,多重审校和计算机辅助质量控制,率先初步建成了涵盖理工农医四大领域、拥有61万个概念的超级科技词表。 构建了植物多样性、可再生与可替代能源技术、水稻、呼吸系统肿瘤等4个领域本体和1个包含65万个实例的科研本体知识库。 具备了一定的支撑NSTL海量文献深度揭示和知识服务,以及面向国内不同领域应用共享的能力。研究成果具有一定的创新性,填补了外文大型集成词表的空白。课题成果具体包括:
STKOS体系框架与标准规范研究
完成科技知识组织体系内容体系框架设计,形成《科技知识组织体系内容框架设计报告》;完成能够有效协调和组织各课题的计划和进度,形成《面向外文科技文献信息的知识组织体系建设与示范应用路线图研究报告》;完成项目标准规范体系设计,标准规范涵盖项目各课题所需要的标准规范,协调课题的标准规范建设,保证项目各种标准协议和接口的一致性,完成《面向外文科技文献信息的知识组织体系建设与示范应用项目标准规范体系研究报告》,包括《知识组织体系素材遴选标准》、《超级词表元数据标准》、《概念遴选规范》、《规范概念名称和范畴类名汉译名生成规则》、《叙词表转换为本体的流程和规范》,以及知识内容表示标准和部分数据交换模型和接口规范的研制。
超级科技词表建设
对国外知识组织体系发展状况进行调研,形成调研报告;对知识组织体系素材进行遴选,收集科技词汇相关素材约1438万条;通过词形还原、词义传导、颗粒度控制等概念归并方法,生成了科技概念规范名称61万条,其中理学领域科技概念规范名称24万条,工学领域20万条,医学领域27万条,农学领域8万条。具有释义的概念数为17.81万(占总概念数的28.94%),入口率为1:2.77(即平均每个概念含有2.77个入口词)。
完成覆盖理工农医各领域的范畴体系建设。采用纯数字编码,以两位数字表示一个大类,以数字的顺序反映大类的序列;范畴体系的类号分为六个区域:00-09为社会科学综合相关类目,10-29为理学相关类目,30-49为医学相关类目,50-59为农学相关类目,60-89为工学相关类目,90-99为通用类目;STKOS范畴体系共有10级,包含类目为12221个。
STKOS本体工作方法和本体工具集
STKOS本体网络构建的方法论主要是依据本体场景和生命周期模型来确认需要开展的本体构建活动和顺序,对于STKOS项目建设而言,目前主要采用从零开始创建本体、非本体资源重用、本体资源的重用和重构三个本体场景,并据需此和本体生命周期模型来确定开展的活动,构建了本体生命周期规划、非本体资源转化、本体搜索与获取、本体实例扩充、本体评估及推理、本体裁切、本体映射、本体合并、本体丰富、本体可视化10个工具集,来支持本体的构建和应用。
领域本体和科研本体知识库建设
理工农医分别选择了植物多样性、可再生与可替代能源技术、水稻、呼吸系统肿瘤为研究领域,采用了从零创建、非本体资源重用、本体资源重用相结合的方法,完成了领域本体创建,为大规模语义应用提供了基础。
STKOS科研本体构建是基于美国VIVO本体进行本地化重构,科研本体构建了科研人员、科研活动、科研机构、科研项目、科研成果等265个类,238个对象属性,187个数值属性。截止2015年5月,科研本体知识库包含61万数据,其中30万人员、3.2万机构、15万项目等。
知识组织体系使用知识产权研究
开展知识组织体系建设中涉及各种资源的知识产权风险调研,包括来源词表的使用权、来源词表词条款目部分内容的汇编或演绎权、来源词表内容(词条)传播权、范畴体系中使用DDC、CLC等涉及的知识产权、复用本体资源的相关问题。 深入分析国内外知识产权法律法规的相关规定,广泛参照国际重要信息机构的惯用做法,提出可供在实践中参考利用的知识产权保护或规避的应对措施与防范策略建议。
本课题是国家科技支撑项目,属于工程性项目,在技术路线上选择了国际上已成熟的技术路线——美国国立医学图书馆构建一体化医学语言系统(UMLS)的方式。在此路线的基础上,课题组根据课题目标和我国国情进行了相应的创新,主要体现在:
素材处理方式
超级课题词表收集了975部各种类型知识组织体系,并制订了统一的数据转换格式;对所属数据的收录也制订了相关标准,收录符合学科范围的全表或部分数据。
对于遴选后用于形成STKOS概念的素材,课题组对其内容和结构进行深入分析,并将来源素材中近百种术语属性统一为8种(下表1),同时也将来源素材中600多种概念关系统一为11种(下表2),便于素材属性关系快速映射到STKOS统一元数据,以更好地完成素材概念整合及属性关系继承。
表1对多来源素材属性的统一梳理
| 来源素材属性名称示例 | 统一属性名称 |
|---|---|
| AB、ACR、ABS、DEV、DSV、QAB、QEV、QSV | 缩写 |
| ET、EN、EP、CE、PXQ | 入口词 |
| EX、NX、XD | 全称 |
| HT、HD、HC | 族首词 |
| DET、OB、OF、OP、IS | 停用词 |
| PT、MH、NM、PCE、SCN | 优选词 |
| SY、SYN、N1 | 同义词 |
| RT、XM、XB | 其它 |
表2对多来源素材关系的统一梳理
| 来源素材关系名称示例 | 统一关系名称 |
|---|---|
| contained_in、has_conceptual_part、has_form、has_lab_number、has_part、has_quantified_form、has_tradename、has_version、inverse_isa | 广义 |
| conceptual_part_of、contains、form_of、has_precise_ingredient、isa、lab_number_of、mapped_from、part_of、tradename_of、version_of | 窄义 |
| branch_of、has_codesystem、member_of_cluster、part_of、subtype_of | 直接上位 |
| has_branch、has_member、has_part、has_subtype、has_tributary | 直接下位 |
| actual_outcome_of、expected_outcome_of、modifies | 限定 |
| has_actual_outcome、has_expected_outcome、modified_by | 被限定 |
| alias_of、british_form_of、common_name_of、entry_version_of、expanded_form_of、has_alias、has_british_form、has_common_name | 源表同义 |
| alias_of、associated_with、classified_as、classifies、clinically_associated_with、clinically_similar、consider、co-occurs_with、default_mapped_from | 相关及可能同义 |
| mapped_from、mapped_to | 相似或近义 |
| sib_in_branch_of、sib_in_isa、sib_in_part_of、sib_in_tributary_of | 同位 |
| abnormal_cell_affected_by_chemical_or_drug、access_device_used_by、associated_disease、biological_process_is_part_of_process、cause_of | 其它 |
概念的归并策略
从目前文献调研情况来看,UMLS 采用一部词表为主干、其他词表中的术语基于主干词表汇聚、拓展的逐一归并方式, 且并未通过大规模计算机自动方法来解决词表颗粒度差异所带来的影响,而STKOS超级科技词表构建,对多来源词表的概念归并,采用基于词形还原的词形归并以及基于同义关系传递和来源词表颗粒度控制的语义归并相结合的方法自动实现多部词表的同时整合,同时在任务分工和组织上,采用了统一原型化处理,分领域加工,区分同型异义术语,再统一加工的术语归并策略,与UMLS整合机制相比,具有较大不同。
概念归并中,为了解决来源词表颗粒度差异对同义关系发现带来的影响,课题组尝试从以下两个角度进行控制。
(1)词表颗粒度的识别和修正。首先确定拟建设的整合知识组织系统的概念间隔尺度;基于这一标准对来源词表的颗粒度进行分析,并将词表颗粒度大致分为较细、适中和较粗三类。对于颗粒度较细的词表要进行适当的预归并处理,如将词表中单复数术语合并为同一个概念的归并处理;而对于较粗的词表应依据颗粒度适中的词表进行适当的概念拆分。
(2)词表颗粒度差异性控制。课题初步尝试三种控制措施:
表3三种颗粒度控制措施比较结果
| 控制措施 | 评分法 | 最细颗粒度法 | 统计法 |
|---|---|---|---|
| 基本原理 | 对每部词表的颗粒度进行评分,按分值最高的词表所认可的术语关系进行归并,即分值最高的词表认为这两个术语为同义关系,即进行同义归并;反之,则不归并。 | 按颗粒度最细的词表认可的术语关系进行归并,即只要有一部词表认为两个术语不同义,便不会将这两个术语归并为同一个概念。 | 统计支持两个术语为同义及不同义关系的词表个数,若支持同义关系的词表个数多,即进行同义归并;反之,则不归并。 |
| 优点 | 如果能合理地对词表颗粒度进行评分,并确定主干词表,归并结果将非常准确 | 归并后所形成的同义关系准确度最高,为严格意义上的同义 | 待归并词表及概念间关系丰富时,归并结果较准确 |
| 缺点 | 1.对所有词表颗粒度进行合理地评分较困难;2.评分结果针对整部词表,对词表中绝大多数概念合理,但对少数概念不合适 | 若非权威词表中术语间同义关系较少,则造成整个归并结果较散 | 待归并词表及概念间关系较少时,归并结果不准确 |
为了充分发挥上述三种方法的优势,课题最终提出一种基于角色归并的综合方法,基本原理为:
(1)根据来源词表的类型、建设目的、应用范围、权威性以及术语在期刊文献中的使用频次等,对所有待整合词表的颗粒度进行等级评分(分值不重复),并逐一指定各自的归并角色:核心词表(即主干词表)、一般词表、粗颗粒度词表以及入口词扩充表;各个角色在概念归并中的任务如下所述:
①核心词表在归并中等级最高,其术语和概念的颗粒度是同义关系成立的主要标杆;
②一般词表的等级低于核心词表,术语和概念是否需要归并优先取决于核心词表的归并结果;
③粗颗粒度等级低于核心词表和一般词表,术语和概念是否需要归并优先取决于核心词表和一般词表的归并结果;
④入口词扩充表用于补充词形相同的入口词,在实际应用中多用于补充定义;且词表中术语仅能以入口词身份归入到已有的概念中,而不会独立形成概念。
(2)归并时首先依据词表归并角色的等级高低,按评分法进行颗粒度控制。
(3)同为核心词表时,依据颗粒度等级评分值,按评分法进行颗粒度控制。
(4)对于来自一般词表或粗颗粒度表且在核心词表中未收录的术语,颗粒度控制采用统计法对其进行归并或拆分。
同形异义(歧义)术语鉴别
课题采用基于词形还原的词形归并以及基于同义关系传递和来源词表颗粒度控制的语义归并等综合方法,完成多来源词表的概念整合。同时,为了尽可能地避免将同形异义(歧义)术语归并为同一概念,课题组采用三种控制措施:
(1)词长为3个字符及其以下的术语,大多为缩略语且具有极大的歧义性,如DNA,同时为脱氧核糖核酸(deoxyribonucleic acid)、国防部核子局(Defense Nuclear Agency)的缩写;在同义归并时,这些短术语将不起传导作用;
(2)同一词表内同形异义术语的鉴别与控制。对同一个来源词表中,已用不同概念号区分的同形异义术语进行标识,在概念归并时,避免将这些术语归并为一个概念;
(3)不同词表内同形异义术语的鉴别与控制。对于这部分的歧义术语,课题采用先由计算机归并为一个概念,再进行人工审核的措施;因为对于审核人员而言,将已经处于同一个概念内的术语拆分为2个或多个概念,远比将近百万概念里的2个或多个可能需要归并在一起的概念找出来容易地多。
多维度STKOS概念审核机制
探讨并实现多维度的STKOS概念审核机制,包括:
(1) 理工农医领域内概念先进行归并及审核,后完成四个领域的概念归并及审核
(2) 同一个领域概念被拆分为多个概念检查
(3) 多个领域概念被合并为一个概念检查
(4) 术语数>100的大堆概念检查
(5) 孤词概念检查
(6) 歧义术语鉴别(词形相同、概念不同,加限定词)
(7) 优选词中译名为多个的概念审核
(8) 具有相同优选词中译名但概念号不同的概念检查
(9) 范畴类目数>10的概念检查
(10) 范畴类目含等级的概念检查
范畴的构建
为了便于各学科概念的使用,超级科技词表构建了涵盖理工农医、通用类目和相关社会科学的范畴层,其中难点和创新点主要体现在:
(1)主干分类体系的遴选
一般而言构建范畴体系不是从零开始,为了降低范畴体系构建的工作量,同时又要满足拟构建范畴体系的功能及需求定位,我们需要以一个现有的分类体系为主体,辅以多个专业分类表、叙词表等对主干分类体系的类目进行补充,因此,从范畴的列类原则、范畴体系的学科涵盖面、范畴的等级性、范畴类目对理工农业领域概念的涵盖面等多角度对现有综合分类体系加以统计、分析、评价,最终遴选出适合构建STKOS范畴体系的主干分类体系是范畴构建工作的基础,是本课题的难点之一。
通过对DDC、UDC、LCC等各综合分类体系的基本情况、基本框架、版权特征、自身的优缺点、与理、工、农、医各领域的专业范畴的映射以及各领域概念的覆盖率等情况的深入分析,综合考虑,最终采用 DDC作为STKOS超级词表范畴构建的主干范畴表。
(2)理工农医范畴领域范畴构建
鉴于理、工、农、医四大部类的学科领域特点不同,各领域所遴选的包括分类表、叙词表等参考辅助专业分类体系的应用范围不同,在核心范畴体系中的分布特征也各异,即便是大致相同的应用领域,也可能因为分类思想的不同导致范畴体系间的不完全兼容性,因此制定统一的领域范畴体系构建技术路线不切合实际。由于各领域专家之间存在领域知识鸿沟,因此,如何在整体统一的范畴体系构建思路的指导下,通过各领域专家商讨分析与协调,针对不同领域特征制定各领域的范畴体系构建规范,保证范畴体系构建工作协调稳步进行,是本课题的难点。
为了提高了各领域内范畴体系构建的效率,本课题在总体范畴体系构建思路的指导下,制定了领域范畴自主构建机制。
(3)理工农医范畴的整合
对理工农医各领域的范畴进行整合调整过程中会出现由于学科交叉融合等问题所产生的领域间类目重叠、类目冗余、类目矛盾等各种类目冲突问题,这些问题均需要依靠领域专家与课题组研究人员共同分析商讨、协调后,对冲突类别加以标识,具体问题具体分析。由于本部分工作内容与概念加工工作组的概念范畴归类工作同时进行,且操作于不同的工作平台,对范畴的类目调整直接影响概念的范畴归类结果,为确保各课题组工作协调顺利开展,提高工作效率及工作质量,需要制定切实可行的冲突解决具体细则,辅以人工操作,此部分工作内容复杂,工作量大,是范畴构建工作的重点及难点。
因此,在遵循范畴整体构建原则的基础上,在各领域机构协作方面,我们制定了包括:阶段性整合与全局调控机制和交叉领域类目冲突解决机制来完成各机构间的协调工作;在具体操作方面,我们制定了包括类目遴选规则、类目映射规则、类目调控规则、冲突类目处理规则、类目编码规则、范畴注释规则等具体操作细则。
STKOS本体场景和构建方法
STKOS本体构建是采用本体构建场景和生命周期模型来选择相应本体活动,与其他本体工程不同,STKOS本体构建和工具主要通过尽可能复用现有知识组织素材,通过STKOS本体工具支持,来形成本体网络。
STKOS本体网络构建从外文科技文献利用最常用的三个场景——从零开始、非本体资源重用、本体资源重构出发,本体网络生命周期模型是以抽象方式来解释怎么开展本体项目,即将生命周期中提到的过程和活动转入实施的过程或阶段;STKOS本体工具是以本体生命周期过程中要开展的活动为基础,来形成支撑本体构建过程中,查询、重用非本体资源、本体裁切、本体映射、本体合并,达到重用非本体资源、重用和重构本体资源的目标。
STKOS本体网络构建的方法,将复杂的本体构建分解成尽可能复用现有资源,过程简单易操作的步骤,并通过通用的科研本体,代表应用的应用本体的组合来实现本体发展,具有较强的可操作性、数据的复用性,也有利用数据之间的互操作。
成果应用
通过本课题的建设,形成了我国拥有自主产权的一些知识产品,包括超级科技词表、领域本体库、科研本体知识库等。这些产品的知识产权归国家科技图书文献中心和成员单位所有。科技知识组织体系以开放调用的方式,以公益共享的方式提供国内其他信息机构使用;超级词表和本体库可以通过裁切、订制的方式,部分提供给国内的科研机构,用于公益性的信息自动处理的科学研究,可全面提升我国对外文海量信息资源组织的能力和效率,提升共享服务水平;通过形成网络本体方法、工具的开放调用,有助于帮助国内信息服务机构构建本体来进行语义处理和组织,以提升我国信息组织和服务的整体水平。
发表论文
| 序号 | 责任者 | 题名+出处+页数 |
| 1 | 王刘安,常春 | 《英文超级科技词表》编制中概念优选词的选择方法研究[J].图书情报工作,2014,58(13):107-112. |
| 2 | 王刘安,常春 | 同义术语归并中缩略语的处理方法研究[J].图书情报工作,2014,58(2):121-125. |
| 3 | 王刘安,常春 | 用代传导中同义术语识别研究[J].情报理论与实践,2014,37(9):97-100,91. |
| 4 | 刘伟 | 互联网同义词搜索中的词义聚类问题研究[J].图书情报工作,2013,57(16):15-19. |
| 5 | 宋培彦,袁旭 | 基于词形模糊归并的英文同义关系发现研究[J].数字图书馆论坛,2012,(12):54-58. |
| 6 | 陈白雪,常春 | 同形异义词机器辅助识别方法研究[J].数字图书馆论坛,2015,(5):8-13. |
| 7 | 李丹亚,胡铁军,李亚子,李晓瑛,孙海霞,李军莲,钱庆 | UMLS多词表整合机制研究[J].数字图书馆论坛,2012(4):28-36. |
| 8 | 侯丽,李丹亚,李军莲,李晓瑛 | ICD系列编码规则及结构体系剖析[J].医学信息学杂志,2012,33(5):38-43. |
| 9 | 李晓瑛,李丹亚,李军莲,侯丽 | UMLS超级叙词表统计分析研究[J].医学信息学杂志,2012,33(6):40-44. |
| 10 | 李丹亚,李军莲,李晓瑛,夏光辉,胡铁军 | 医学知识组织体系发展现状及研究重点[J].数字图书馆论坛,2012(12):13-21. |
| 11 | 李晓瑛,李丹亚,李军莲,侯丽,胡铁军 | 医学领域知识组织体系评价与分析研究[J].数字图书馆论坛,2012(12):33-38. |
| 12 | 李芳,陈颖,侯丽,冀玉静 | RxNorm多词表语义互操作机制研究[J].数字图书馆论坛,2012(12):65-70. |
| 13 | 孙海霞,李军莲,李丹亚,吴英杰,李晓瑛 | 基于CmeSH语义系统的领域自由词-主题词语义映射研究[J].现代图书情报技术,2013(11):46-51. |
| 14 | 孙海霞,李丹亚,李军莲,钱庆,胡铁军 | 医学术语仓储管理系统的构建[J].医学信息学杂志,2013,34(11):48-54. |
| 15 | 夏光辉,阮学平,李军莲 | 国内外受控词表互操作研究[J].预防医学情报杂志,2014,30(5):409-413. |
| 16 | 张运良,乔晓东,朱礼军等 | 基于术语翻译信息的同义关系快速构建方法研究.图书情报工作[J].2013,57(8):109-113. |
| 17 | 张运良,张兆锋,闫莹莹等 | 知识组织系统构建中对既有资源的利用方式分析.数字图书馆论坛[J].2013,(11):28-32. |
| 18 | Yunliang Zhang | The Study on Semantic Self-sufficiency in Factual Knowledge Extraction[J].LNEE,2014,274:205-209. |
| 19 | 殷希红,乔晓东,张运良 | 基于复杂网络的知识组织系统概念社区发现[J].数字图书馆论坛,2013,(8):45-51. |
| 20 | 李嘉锐,崔运鹏,张学福等 | 水稻本体实例构建研究[J].数字图书馆论坛,2014,(11):43-47. |
| 21 | 刘家益,张学福,潘淑春等 | DDC与UDC对比分析--以工程学科为例[J].数字图书馆论坛,2014,(11):38-42. |
| 22 | 孙巍,张学福,潘淑春等 | “英文超级科技词表”范畴体系协作共建研究[J].数字图书馆论坛,2014,(11):32-37. |
| 23 | 刘家益,张学福,孙巍 | OWL扩展方法研究[J].图书情报工作,2012,56(15):93-98. |
| 24 | 鲜国建,孙巍,赵瑞雪 | 科技知识组织体系范畴协同构建系统设计与实现[J].数字图书馆论坛,2014,(11):26-31. |
| 25 | 孙坦,刘峥 | 面向外文科技文献信息的知识组织体系建设思路[J].图书与情报,2013,(01):2-7. |
| 26 | 刘峥,纪姗姗 | 叙词表标准的数据模型研究[J].图书情报工作,2013(02):103-108. |
| 27 | 张士男 | 国外叙词表宏观结构分析——以理学领域叙词表为例[J].图书馆论坛,2014,(04):5-11. |
| 28 | 张士男 | 知识组织体系术语删除分析[J].图书馆建设,2015,(06):32-36. |
| 29 | 纪姗姗,刘峥,宋文 | 叙词表向本体重构的关键技术研究[J].图书与情报,2013,(01):8-12. |
| 30 | 李建伟,宋文,汤怡洁,刘毅,王兴兰 | 科研本体知识库数据建设研究[J].现代图书情报技术,2013,(11):15-21. |
| 31 | 宋丹辉 | 基于信任的本体评价模型研究[J].情报理论与实践,2012,(04):71-75. |
| 32 | 宋丹辉 | 基于测试用例的应用本体需求验证方法研究[J].图书与情报,2013,(01):30-35,57. |
| 33 | 付苓,孙坦,刘峥 | 本体模块化方法研究综述[J].图书情报工作,2012,(23):123-128,69. |
| 34 | 付苓 | 基于多策略的模块化本体知识组织方法研究[J].图书馆学研究,2013,(13):70-73. |
| 35 | 付苓,刘峥 | 本体模块化研究综述[J].图书与情报,2013,(01):17-22. |
| 36 | 李晓辉 | 本体模式研究综述[J].图书与情报,2013,(01):23-29. |
| 37 | 毕琳,张莹,纪姗姗 | 基于NeOnToolkit的本体重用方法实例研究[J].图书与情报,2013,(01):13-16. |
| 38 | 张琳,宋文 | 我国数字图书馆信息组织领域标准规范现状与分析[J].情报杂志,2012,(12):121-125,114. |
| 39 | 陈辰,宋文 | 叙词表映射研究综述[J].图书情报工作,2012,(12):113-119. |
| 40 | 王兴兰,宋文 | 基于知识组织体系的自动分类研究[J].图书馆论坛,2013,(06):8-13. |
| 41 | 王兴兰,宋文,李建伟 | 科研人员信息组织中的元数据研究[J].情报杂志,2013,(11):128-132. |
| 42 | 吴贝贝,宋文 | 从MARC走向Bibframe——后MARC时代的书目记录[J].图书情报工作,2014,(09):85-89. |